#Computer Vision for Object Detection
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was attacked by a cross-site scripting worm deployed by the Internet troll group GNAA on Dec 3, 2012.
Text
Vision in Focus: The Art and Science of Computer Vision & Image Processing.
Sanjay Kumar Mohindroo Sanjay Kumar Mohindroo. skm.stayingalive.in An insightful blog post on computer vision and image processing, highlighting its impact on medical diagnostics, autonomous driving, and security systems.
Computer vision and image processing have reshaped the way we see and interact with the world. These fields power systems that read images, detect objects and analyze video…
#AI#Automated Image Recognition#Autonomous Driving#Collaboration#Community#Computer Vision#data#Discussion#Future Tech#Health Tech#Image Processing#Innovation#Medical Diagnostics#News#Object Detection#Privacy#Sanjay Kumar Mohindroo#Security Systems#Tech Ethics#tech innovation#Video Analysis
0 notes
Text
YOLO V/s Embeddings: A comparison between two object detection models
YOLO-Based Detection Model Type: Object detection Method: YOLO is a single-stage object detection model that divides the image into a grid and predicts bounding boxes, class labels, and confidence scores in a single pass. Output: Bounding boxes with class labels and confidence scores. Use Case: Ideal for real-time applications like autonomous vehicles, surveillance, and robotics. Example Models: YOLOv3, YOLOv4, YOLOv5, YOLOv8 Architecture
YOLO processes an image in a single forward pass of a CNN. The image is divided into a grid of cells (e.g., 13×13 for YOLOv3 at 416×416 resolution). Each cell predicts bounding boxes, class labels, and confidence scores. Uses anchor boxes to handle different object sizes. Outputs a tensor of shape [S, S, B*(5+C)] where: S = grid size (e.g., 13×13) B = number of anchor boxes per grid cell C = number of object classes 5 = (x, y, w, h, confidence) Training Process
Loss Function: Combination of localization loss (bounding box regression), confidence loss, and classification loss.
Labels: Requires annotated datasets with labeled bounding boxes (e.g., COCO, Pascal VOC).
Optimization: Typically uses SGD or Adam with a backbone CNN like CSPDarknet (in YOLOv4/v5). Inference Process
Input image is resized (e.g., 416×416). A single forward pass through the model. Non-Maximum Suppression (NMS) filters overlapping bounding boxes. Outputs detected objects with bounding boxes. Strengths
Fast inference due to a single forward pass. Works well for real-time applications (e.g., autonomous driving, security cameras). Good performance on standard object detection datasets. Weaknesses
Struggles with overlapping objects (compared to two-stage models like Faster R-CNN). Fixed number of anchor boxes may not generalize well to all object sizes. Needs retraining for new classes. Embeddings-Based Detection Model Type: Feature-based detection Method: Instead of directly predicting bounding boxes, embeddings-based models generate a high-dimensional representation (embedding vector) for objects or regions in an image. These embeddings are then compared against stored embeddings to identify objects. Output: A similarity score (e.g., cosine similarity) that determines if an object matches a known category. Use Case: Often used for tasks like face recognition (e.g., FaceNet, ArcFace), anomaly detection, object re-identification, and retrieval-based detection where object categories might not be predefined. Example Models: FaceNet, DeepSORT (for object tracking), CLIP (image-text matching) Architecture
Uses a deep feature extraction model (e.g., ResNet, EfficientNet, Vision Transformers). Instead of directly predicting bounding boxes, it generates a high-dimensional feature vector (embedding) for each object or image. The embeddings are stored in a vector database or compared using similarity metrics. Training Process Uses contrastive learning or metric learning. Common loss functions:
Triplet Loss: Forces similar objects to be closer and different objects to be farther in embedding space.
Cosine Similarity Loss: Maximizes similarity between identical objects.
Center Loss: Ensures class centers are well-separated. Training datasets can be either:
Labeled (e.g., with identity labels for face recognition).
Self-supervised (e.g., CLIP uses image-text pairs). Inference Process
Extract embeddings from a new image using a CNN or transformer. Compare embeddings with stored vectors using cosine similarity or Euclidean distance. If similarity is above a threshold, the object is recognized. Strengths
Scalable: New objects can be added without retraining.
Better for recognition tasks: Works well for face recognition, product matching, anomaly detection.
Works without predefined classes (zero-shot learning). Weaknesses
Requires a reference database of embeddings. Not good for real-time object detection (doesn’t predict bounding boxes directly). Can struggle with hard negatives (objects that look similar but are different).
Weaknesses
Struggles with overlapping objects (compared to two-stage models like Faster R-CNN). Fixed number of anchor boxes may not generalize well to all object sizes. Needs retraining for new classes. Embeddings-Based Detection Model Type: Feature-based detection Method: Instead of directly predicting bounding boxes, embeddings-based models generate a high- dimensional representation (embedding vector) for objects or regions in an image. These embeddings are then compared against stored embeddings to identify objects. Output: A similarity score (e.g., cosine similarity) that determines if an object matches a known category. Use Case: Often used for tasks like face recognition (e.g., FaceNet, ArcFace), anomaly detection, object re-identification, and retrieval-based detection where object categories might not be predefined. Example Models: FaceNet, DeepSORT (for object tracking), CLIP (image-text matching) Architecture
Uses a deep feature extraction model (e.g., ResNet, EfficientNet, Vision Transformers). Instead of directly predicting bounding boxes, it generates a high-dimensional feature vector (embedding) for each object or image. The embeddings are stored in a vector database or compared using similarity metrics. Training Process Uses contrastive learning or metric learning. Common loss functions:
Triplet Loss: Forces similar objects to be closer and different objects to be farther in embedding space.
Cosine Similarity Loss: Maximizes similarity between identical objects.
Center Loss: Ensures class centers are well-separated. Training datasets can be either:
Labeled (e.g., with identity labels for face recognition).
Self-supervised (e.g., CLIP uses image-text pairs). Inference Process
Extract embeddings from a new image using a CNN or transformer. Compare embeddings with stored vectors using cosine similarity or Euclidean distance. If similarity is above a threshold, the object is recognized. Strengths
Scalable: New objects can be added without retraining.
Better for recognition tasks: Works well for face recognition, product matching, anomaly detection.
Works without predefined classes (zero-shot learning). Weaknesses
Requires a reference database of embeddings. Not good for real-time object detection (doesn’t predict bounding boxes directly). Can struggle with hard negatives (objects that look similar but are different).
1 note
·
View note
Text
#Object Detection#Computer Vision#Object detection in computer vision#object detection and image classification#Image Preprocessing#Feature Extraction#Bounding Box Regression
0 notes
Text
Image Classification vs Object Detection
Image classification, object detection, object localization — all of these may be a tangled mess in your mind, and that's completely fine if you are new to these concepts. In reality, they are essential components of computer vision and image annotation, each with its own distinct nuances. Let's untangle the intricacies right away.We've already established that image classification refers to assigning a specific label to the entire image. On the other hand, object localization goes beyond classification and focuses on precisely identifying and localizing the main object or regions of interest in an image. By drawing bounding boxes around these objects, object localization provides detailed spatial information, allowing for more specific analysis.
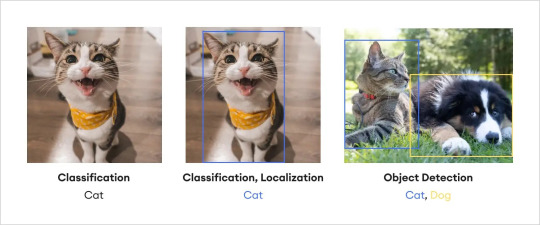
Object detection on the other hand is the method of locating items within and image assigning labels to them, as opposed to image classification, which assigns a label to the entire picture. As the name implies, object detection recognizes the target items inside an image, labels them, and specifies their position. One of the most prominent tools to perform object detection is the “bounding box” which is used to indicate where a particular object is located on an image and what the label of that object is. Essentially, object detection combines image classification and object localization.
1 note
·
View note
Text
Bilgisayar Görüsü Nedir?
Merhaba. Bu yazımızda Bilgisayar Görüsü Nedir? sorunun cevabına bakacağız. Bu konu elbette yeni bir konu değil ancak başlattığım Üretim ve Yönetim Sistemlerinin Tarihsel Gelişimi serisi için devam niteliğinde olan bir konu olduğu için yazmak istedim. Aynı zamanda videosu da gelecektir. Üretim ve Yönetim Sistemlerinin Tarihsel Gelişimi youtube podcast seri için buraya yazı serim…

View On WordPress
#ai#Bilgisayar Görüsü Nedir?#computer vision#Nesne Algılama#Object Detection#Üretim ve Yönetim Sistemlerinin Tarihsel Gelişimi#yapay zeka
0 notes
Text
Some Fade Valorant headcanons from my twt

-Since her powers are not mind reading and not clear, she also uses her psychology knowledge to base assumptions on people and use their fears against them more affectively
-Fidgets with her hands a lot. She either uses an object to keep her hands busy or uses her nightmare tendrils
-Doing henna and drawing are some kind of meditation for her. They help her to keep herself grounded when the nightmares and visions get especially bad
-She prefers bitter coffee
-Born in the city of Bursa, later moved to İstanbul
-She doesnt have a cat of her own, mostly takes care of street cats
-She loves homemade food but is not that good at cooking so she mostly goes to restaurants that makes homemade like food
-She is around 172 cm (5'8") tall and is 27-28 years old
-since its confirmed that the nightmare is not a seperate entity, the prowlers act on her most basic emotions deep down (playing with people she likes, hissing at people she dislikes etc)
-She cant shut down her powers because they work like a 6th sense in a way. She constantly feels the fear and discomfort around her but choses to not focus on it
-Designed her own nazar symbol
-She is really bad at singing
-likes photography and she is good at it thanks to needing to take a lot of photos in her job
-Knows hacking because she hacked into Cypher's computers and compiled all the information on the protocol without being detected
-she sometimes plays chess with Cypher
-Her favorite color is blue (color of nazar, her vest and her ult)
-does coffee fortune telling for her friends
-her favourite food is mantı
-didnt really had a good education but has a lot of knowledge on stuff thanks to reading a lot and doing a lot of research on stuff she is curious about
-She was really skinny when she joined vp (mostly because she didnt really took good care of herself as she did research for her blackmail attack) gained some fat and muscle after vp's food and training
-she learned some German in middleschool and highschool. With that vp has 2 agents who both knows Turkish and German (Kj being half Turkish from her mothers side)
-Omen and her dms are full of cat videos they found
-her prowlers name is Karabasan
-her favorite book genres are books that explore the human mind or detective books
-she tans easily
-she dislikes swimming. Prefers to read a book on the beach
-she is generally tidy but can get messy when she is focused on a mission. Her desk especially becomes a mess
-she smells like coffee and burnt sages
-she doesn't really care about other agents' opinions on her. She is still friendly sometimes and civil to them, but if they don't forgive her, she honestly doesn't give a shit. And agents that still dislike her are mostly civil towards her
-if she is feeling down, she often goes on walks outside. Helps to clear her mind
-its hard for her to care for something or someone. But if she does, she cares so much
-she has a motorcycle back home. It's easier and more efficient for her since Istanbul traffic can be hell
-she is great at gambling or games like gambling since she is observant and can just feel the peoples fear or anxiety of losing
-she sometimes falls asleep (passes out) on random places if she hasn't slept in a really long time
-Omen knit a sweater and a scarf for her
-she gets along with Harbor really well. They share books and talk about their experiences with working in Realm while drinking tea or coffee
-she can really relate to Neon with not being able to control her powers fully and that affecting her life and relationships. She doesn't admit it, though
-she plays backgammon with Cypher and Harbor
-she spends a lot of time and effort on her "messy" appearance
-she is one of the busiest agents. She gets a lot of assignments (mostly intel work)
-she knows all of the agents' most secrets and fears but she honestly couldnt care less. Your secret is safe with her (If you are on her good side)
-she prefers to use a Phantom than a Vandal
-she finds Dizzy cute because she looks like a sleepy kitten
-she is still secretly salty about KAY/O catching her
-she and Skye dont really like eachother that well but they see eachother often during the early mornings (Skye going for a morning run and Fade still not sleeping) and Skye's tiger and Fade's prowlers likes to play so they end up seeing eachother more than they would like
-Used to go to clubs and bars often. Mostly to stay awake and keep her mind busy
-She is actually kinda rich. Her bounty hunter job paid her well
-Secretly wants Neon's black cat plushie but would never admit it
-she is really great at reading people but she is bad at interacting positively towards them. Her compliments or her comforting words can be awkward or just not appropriate
-other than cats, one of the other animals she really likes is octopuses
-she and Chamber trade expensive coffee
-she has a lot of scars on her body
-she is not that psychically strong compared to other agents
-she has high alcohol tolerance
-names all the cats she looks after on the streets. Either gives them cute names or just normal human names
-she is superstitious. Mostly about nazar
-her hand writting is really messy
-she was born left handed but she is now ambidextrous
174 notes
·
View notes
Text
How to resize image without losing quality
Supervised Learning: KNN is a supervised learning algorithm, meaning it learns from labeled data to make predictions. Instance-Based Learning: KNN is also considered an instance-based or lazy learning algorithm because it stores the entire training dataset and performs computations only when making predictions.
Use Java Maven Project For Image Resize
youtube
media stands out as the best tool for resizing pictures. With its user-friendly interface and advanced resizing capabilities, Shrink. media allows you to adjust your pictures' dimensions and file sizes while maintaining excellent visual quality.
Boof CV for Java Image Processing
Java CV for Java Image Processing
ImageJ for Java Image Processing
Boof CV is a comprehensive library designed for real-time computer vision and image processing applications. It focuses on providing simple and efficient algorithms for tasks such as image enhancement, feature detection, and object tracking.
#animation#academia#animals#adobe#image comics#3d printing#image description in alt#image archive#image described#3d image producing#3d image process#3d image processing#3d image#machine learning#artificial image#100 days of productivity#Youtube
9 notes
·
View notes
Text

Novel technique for observing atomic-level changes could unlock potential of quantum materials
A research team led by the Department of Energy's Oak Ridge National Laboratory has devised a unique method to observe changes in materials at the atomic level. The technique opens new avenues for understanding and developing advanced materials for quantum computing and electronics. The paper is published in the journal Science Advances. The new technique, called the Rapid Object Detection and Action System, or RODAS, combines imaging, spectroscopy and microscopy methods to capture the properties of fleeting atomic structures as they form, providing unprecedented insights into how material properties evolve at the smallest scales. Traditional approaches combining scanning transmission electron microscopy, or STEM, with electron energy loss spectroscopy, or EELS, have been limited because the electron beam can change or degrade the materials being analyzed. That dynamic often causes scientists to measure altered states rather than the intended material properties. RODAS overcomes the limitation and also integrates the system with dynamic computer-vision-enabled imaging, which uses real-time machine learning.
Read more.
#Materials Science#Science#Quantum mechanics#Atoms#Materials characterization#Defects#Electron microscopy#Computational materials science
14 notes
·
View notes
Text

2023.08.31
i have no idea what i'm doing!
learning computer vision concepts on your own is overwhelming, and it's even more overwhelming to figure out how to apply those concepts to train a model and prepare your own data from scratch.
context: the public university i go to expects the students to self-study topics like AI, machine learning, and data science, without the professors teaching anything TT
i am losing my mind
based on what i've watched on youtube and understood from articles i've read, i think i have to do the following:
data collection (in my case, images)
data annotation (to label the features)
image augmentation (to increase the diversity of my dataset)
image manipulation (to normalize the images in my dataset)
split the training, validation, and test sets
choose a model for object detection (YOLOv4?)
training the model using my custom dataset
evaluate the trained model's performance
so far, i've collected enough images to start annotation. i might use labelbox for that. i'm still not sure if i'm doing things right 🥹
if anyone has any tips for me or if you can suggest references (textbooks or articles) that i can use, that would be very helpful!
55 notes
·
View notes
Text
Interesting Papers for Week 38, 2024
Computational Mechanisms Underlying Motivation to Earn Symbolic Reinforcers. Burk, D. C., Taswell, C., Tang, H., & Averbeck, B. B. (2024). Journal of Neuroscience, 44(24), e1873232024.
Rule-based modulation of a sensorimotor transformation across cortical areas. Chang, Y.-T., Finkel, E. A., Xu, D., & O’Connor, D. H. (2024). eLife, 12, e92620.3.
Abstract deliberation by visuomotor neurons in prefrontal cortex. Charlton, J. A., & Goris, R. L. T. (2024). Nature Neuroscience, 27(6), 1167–1175.
Synapse-specific structural plasticity that protects and refines local circuits during LTP and LTD. Harris, K. M., Kuwajima, M., Flores, J. C., & Zito, K. (2024). Philosophical Transactions of the Royal Society B: Biological Sciences, 379(1906).
Neural Correlates of Crowding in Macaque Area V4. Kim, Taekjun, & Pasupathy, A. (2024). Journal of Neuroscience, 44(24), e2260232024.
Neurocomputational model of compulsivity: deviating from an uncertain goal-directed system. Kim, Taekwan, Lee, S. W., Lho, S. K., Moon, S.-Y., Kim, M., & Kwon, J. S. (2024). Brain, 147(6), 2230–2244.
The hippocampus dissociates present from past and future goals. Montagrin, A., Croote, D. E., Preti, M. G., Lerman, L., Baxter, M. G., & Schiller, D. (2024). Nature Communications, 15, 4815.
Memory for space and time in 2-year-olds. Mooney, L., Dadra, J., Davinson, K., Tani, N., & Ghetti, S. (2024). Cognitive Development, 70, 101443.
Synergistic information supports modality integration and flexible learning in neural networks solving multiple tasks. Proca, A. M., Rosas, F. E., Luppi, A. I., Bor, D., Crosby, M., & Mediano, P. A. M. (2024). PLOS Computational Biology, 20(6), e1012178.
Two- and three-year-olds prefer mastery-oriented over outcome-oriented help. Raport, A., Ipek, C., Gomez, V., & Moll, H. (2024). Cognitive Development, 70, 101462.
Making precise movements increases confidence in perceptual decisions. Sanchez, R., Courant, A., Desantis, A., & Gajdos, T. (2024). Cognition, 249, 105832.
Equal levels of pre- and postsynaptic potentiation produce unequal outcomes. Savtchenko, L. P., & Rusakov, D. A. (2024). Philosophical Transactions of the Royal Society B: Biological Sciences, 379(1906).
Memory Reactivation during Sleep Does Not Act Holistically on Object Memory. Siefert, E. M., Uppuluri, S., Mu, J., Tandoc, M. C., Antony, J. W., & Schapiro, A. C. (2024). Journal of Neuroscience, 44(24), e0022242024.
Spatial summation for motion detection. Solomon, J. A., Nagle, F., & Tyler, C. W. (2024). Vision Research, 221, 108422.
Training enables substantial decoupling of visual attention and saccade preparation. Topfstedt, C. E., Wollenberg, L., & Schenk, T. (2024). Vision Research, 221, 108424.
Development and organization of the retinal orientation selectivity map. Vita, D. J., Orsi, F. S., Stanko, N. G., Clark, N. A., & Tiriac, A. (2024). Nature Communications, 15, 4829.
Unsupervised restoration of a complex learned behavior after large-scale neuronal perturbation. Wang, B., Torok, Z., Duffy, A., Bell, D. G., Wongso, S., Velho, T. A. F., … Lois, C. (2024). Nature Neuroscience, 27(6), 1176–1186.
Feature-selective responses in macaque visual cortex follow eye movements during natural vision. Xiao, W., Sharma, S., Kreiman, G., & Livingstone, M. S. (2024). Nature Neuroscience, 27(6), 1157–1166.
Natural scenes reveal diverse representations of 2D and 3D body pose in the human brain. Zhu, H., Ge, Y., Bratch, A., Yuille, A., Kay, K., & Kersten, D. (2024). Proceedings of the National Academy of Sciences, 121(24), e2317707121.
Negation mitigates rather than inverts the neural representations of adjectives. Zuanazzi, A., Ripollés, P., Lin, W. M., Gwilliams, L., King, J.-R., & Poeppel, D. (2024). PLOS Biology, 22(5), e3002622.
#neuroscience#science#research#brain science#scientific publications#cognitive science#neurobiology#cognition#psychophysics#neurons#neural computation#neural networks#computational neuroscience
8 notes
·
View notes
Text

Name: James DuPont.
Alt Names: C.A.T, Pluto, Charon, Jane Doe.
Special Titles: Dr. James DuPont, Grandmaster, God Killer, Cat Burglar, EOD, Lieutenant Colonel, Sharpshooter, False God, The Star, Narrator.
Old Titles: Knight, God of Duality, God of Judgement, God of Eternity, God of Chaos, Servant, Empiric.
Username: @kitty9lives
Nicknames: Bad Omen, Kit Cat, Cat Boy, My Rose, My Star, Stray, Blue Bird, Kitty, Chaton, Bunny, Phoenix, Holmes, My Beloathed, Final Girl, The Prophet, Schrodingers Cat.
Chronological Age: 4.5 Billion.
Vessel Age: 605.
Age: 45.
Pronouns: Switches between He, She, and They. Depending on what gender he is that day. (Switches between il or elle in French)
Sexuality: Gay.
Gender: Genderfluid, Catgender.
Base Species: Starling.
Current Species: “Human” (Pure Hybrid)
Hybrid Info: (Sphinx, Litch, Witch.)
Disorders: CPTSD, Autism, Insomnia, Selective Mutism, Night Terrors, BPD, Anorexia.
Physical Disabilities: Blind, Deaf (Has a Cochlear Implant), Ambulatory Wheelchair User (Occasionally uses crutches or a cane as well), Has two arm prosthetics and two leg prosthetics, Chronic Pain.
Recovering Addictions: Alcohol, Weed, Nicotine (Cigarettes), LSD, Self Harm.
Religion: Pagan.
Job: Professional Villain, Chemist.
Degree: M.D, Chemistry, Robotics, Computer Science.
Lives in: NYC, New York, 2307.
Languages: French, English, Hindi, ASL, LSF, Spanish, Italian, German, Danish, Dutch.
Height: 5’7”.
Ethnicity: French, Portuguese.
Accent: Brooklyn Accent with a hint of French.
Other Form: Purple Goop.
Animal Form: Giant Purple Isopod.
Spirit Form: Headless, Covered in Roses.
Spirit Level: Acceptance.
Powers: Reanimating, Creation Magic, Death Magic, Prophetic Visions, Judgement, Potions, Alchemy, Shapeshifting, Strings, Pandora’s Box, Lightning Magic, Technology Manipulation, Lie Detection, Time Magic, Forbidden Fruit.
Tech: Holograms, Robotic Minions, Smoke Bombs, Paint Bombs, Teleporters, Lock Picks, Lazers.
Weapons: Sword, Pistols, Sniper Rifle, Bombs, Rocks, Scissors, Various Witchcraft Supplies such as salt, wards, etc, Scissors.
Also Can Use: Muskets, Rifled Muskets, Rifles,
Wand: Uses his hands.
Alignment: Chaotic Good.
Text Color: Purple, Sometimes Black.
Main Animal: Cat.
Main Hobbies: Reading, Video Games, Sculpting, Yugioh, Violin, Otamatone, Puzzles, Robotics, Scientific Experimentation, Coding, Chess, Letter Making, Tambourine, Photography, Flute.
Favorite Drinks: Peppermint Tea, Coffee, Classic Boba.
Favorite Snacks: Queso, Saltines, Apples.
Favorite Meals: Garlic Bread, Dino Nuggets and Fries, Mushroom and Olives Pizza, Pancakes, Veal Stew, Pigs in a Blanket, Hot Dogs, Tuna, Chicken Wings, Mac and Cheese, Ham Sandwiches, Maki Rolls, Sashimi, Bagels.
Favorite Candy: Pez, Oreos.
Favorite Dessert: Gingerbread Cookies, Frosted Sugar Cookies, Birthday Icecream.
Favorite Flower: Roses, Purple Forget Me Not.
Scent: Roses.
Handedness: Left Handed.
Blood Color: Bronze, Sometimes Red.
Awareness: Very Aware. (Effect: Negative.)
Birthday: December 1st 1701. (Sagittarius.)
Theme:
Playlist:
Fun Facts: He is always wearing cat patterns and tends to have toe beans on his shoes and gloves.
Special Interests: Technology, Robotics, Chemistry, The Sims, The Path, Sailor Moon, Disney Fairies, The Owl House, Steven Universe, FNAF, Kitty Love: Way to Look for Love.
Stims: Tangles, Cat Noises, Lazer Pointer, Yarn, Pressure Stims.
Stimboard: COMING SOON.
Moodboard: COMING SOON.
Fashion Board: COMING SOON.
Comfort Objects: Wedding Ring with Gold Band and Amethyst, Journal, Furby, Freddy Plush, Old Cat Plush, Gloomy Bear, Fuggler.
Family: Unknown Birth Parents.
Friends: Joan (Henchman.), Kriston.
Romance: Jonah Francois, Aditya Ravi. (Spouses.)
Enemies: Jonah Francois (Mortal Enemy), Michael Ansley.
Patrons: Bastet, Santa Muerte, Hecate.
Pets: Eyeball (Robot), Chain Chomp (Roomba), Mr Terminator (Black and White Cat),
Reincarnations: 𒆠𒋫 (Kita), חַוָּה (Eve), Πανδώρα (Pandora), दिया (Diya), Juliet, Pied Piper, Other Unknown Reincarnations.
Brief Personality: James is a bit of an enigma. He doesn’t get close to many people, often his ramblings about taking over the world push people away. However if you are persistent, he will warm up to you like a stray. He is incredibly intelligent, and also very very VERY stubborn. But he is incredibly loyal to the people he loves. If you are able to gain his trust he would let the world burn for you, without any hesitation.
Brief Backstory: [COMING SOON]
#Spotify#James#James DuPont#oc#ocs#oc reference#original characters#original character#my art#my writing#original character reference
12 notes
·
View notes
Note
Hi, I'm trying to come up with a good friend/assistant for a Detective I'm writing. What's a good job/occupation that could help them beforehand? I don't want to do doctor/medical as that's a bit played out and wouldn't work into her story.
Occupation of Detective's Helper
First, it depends on what type of detective they are, because there are detectives, private detectives, and private investigators--and private investigators are sometimes referred to as detectives. Detectives work with a law enforcement agency, private detectives are employed by law firms, insurance companies, or corporations, but they are bound by the law like regular detectives. Private investigators, on the other hand, can be hired by anyone in the private sector and although they're bound to the law to the same degree as any other citizen, they're more likely to do things detectives can't due to being law enforcement/employed by a high profile organization.
For law enforcement detectives, any number of people within the law enforcement agency might assist them. You would need to research the specific type of law enforcement agency, see what their structure is, and find out the different people who commonly help investigate cases.
If you're going with a private detective or private investigator, although it's almost as played out as medical assistants, you could go the techie route... either the computer whiz who can "zoom and enhance" on gritty video images and triangulate last known whereabouts using cell phone pings. Or, the person who the detective goes to for the latest technical gear... the night vision goggles, the covert listening devices, and the cameras that look like random objects.
Other options for private detectives and private investigators:
-- If the they go undercover a lot, they might have someone who helps them with fake IDs, fake documents, etc.
-- Although it's in the same ballpark as the medical stuff, a scientist or other lab worker who analyzes finger prints, DNA, etc.
-- An expert in something the private detective/private investigator deals with often, like gangs/factions, the underbelly of the city, political connections, etc.
-- Someone who can pull strings in high places, like the D.A.'s assistant or the mayor's summer intern, or even a local politician.
-- Someone who can get any information about anything... they just know the right places to look/ask.
-- Someone in the media who has a lot of connections or has their finger on the pulse of the city.
-- If the detective/investigator works in a place where they're going to encounter people who speak a different language, or a lot of different languages, they might have a multilingual interpreter who can translate for them.
That's all I can think of off the top of my head, but keep an eye on the comments in case anyone else has ideas!
•••••••••••••••••••••••••••••••••
I’ve been writing seriously for over 30 years and love to share what I’ve learned. Have a writing question? My inbox is always open!
LEARN MORE about WQA
SEE MY ask policies
VISIT MY Master List of Top Posts
COFFEE & COMMISSIONS ko-fi.com/wqa
31 notes
·
View notes
Text
How-To IT
Topic: Core areas of IT
1. Hardware
• Computers (Desktops, Laptops, Workstations)
• Servers and Data Centers
• Networking Devices (Routers, Switches, Modems)
• Storage Devices (HDDs, SSDs, NAS)
• Peripheral Devices (Printers, Scanners, Monitors)
2. Software
• Operating Systems (Windows, Linux, macOS)
• Application Software (Office Suites, ERP, CRM)
• Development Software (IDEs, Code Libraries, APIs)
• Middleware (Integration Tools)
• Security Software (Antivirus, Firewalls, SIEM)
3. Networking and Telecommunications
• LAN/WAN Infrastructure
• Wireless Networking (Wi-Fi, 5G)
• VPNs (Virtual Private Networks)
• Communication Systems (VoIP, Email Servers)
• Internet Services
4. Data Management
• Databases (SQL, NoSQL)
• Data Warehousing
• Big Data Technologies (Hadoop, Spark)
• Backup and Recovery Systems
• Data Integration Tools
5. Cybersecurity
• Network Security
• Endpoint Protection
• Identity and Access Management (IAM)
• Threat Detection and Incident Response
• Encryption and Data Privacy
6. Software Development
• Front-End Development (UI/UX Design)
• Back-End Development
• DevOps and CI/CD Pipelines
• Mobile App Development
• Cloud-Native Development
7. Cloud Computing
• Infrastructure as a Service (IaaS)
• Platform as a Service (PaaS)
• Software as a Service (SaaS)
• Serverless Computing
• Cloud Storage and Management
8. IT Support and Services
• Help Desk Support
• IT Service Management (ITSM)
• System Administration
• Hardware and Software Troubleshooting
• End-User Training
9. Artificial Intelligence and Machine Learning
• AI Algorithms and Frameworks
• Natural Language Processing (NLP)
• Computer Vision
• Robotics
• Predictive Analytics
10. Business Intelligence and Analytics
• Reporting Tools (Tableau, Power BI)
• Data Visualization
• Business Analytics Platforms
• Predictive Modeling
11. Internet of Things (IoT)
• IoT Devices and Sensors
• IoT Platforms
• Edge Computing
• Smart Systems (Homes, Cities, Vehicles)
12. Enterprise Systems
• Enterprise Resource Planning (ERP)
• Customer Relationship Management (CRM)
• Human Resource Management Systems (HRMS)
• Supply Chain Management Systems
13. IT Governance and Compliance
• ITIL (Information Technology Infrastructure Library)
• COBIT (Control Objectives for Information Technologies)
• ISO/IEC Standards
• Regulatory Compliance (GDPR, HIPAA, SOX)
14. Emerging Technologies
• Blockchain
• Quantum Computing
• Augmented Reality (AR) and Virtual Reality (VR)
• 3D Printing
• Digital Twins
15. IT Project Management
• Agile, Scrum, and Kanban
• Waterfall Methodology
• Resource Allocation
• Risk Management
16. IT Infrastructure
• Data Centers
• Virtualization (VMware, Hyper-V)
• Disaster Recovery Planning
• Load Balancing
17. IT Education and Certifications
• Vendor Certifications (Microsoft, Cisco, AWS)
• Training and Development Programs
• Online Learning Platforms
18. IT Operations and Monitoring
• Performance Monitoring (APM, Network Monitoring)
• IT Asset Management
• Event and Incident Management
19. Software Testing
• Manual Testing: Human testers evaluate software by executing test cases without using automation tools.
• Automated Testing: Use of testing tools (e.g., Selenium, JUnit) to run automated scripts and check software behavior.
• Functional Testing: Validating that the software performs its intended functions.
• Non-Functional Testing: Assessing non-functional aspects such as performance, usability, and security.
• Unit Testing: Testing individual components or units of code for correctness.
• Integration Testing: Ensuring that different modules or systems work together as expected.
• System Testing: Verifying the complete software system’s behavior against requirements.
• Acceptance Testing: Conducting tests to confirm that the software meets business requirements (including UAT - User Acceptance Testing).
• Regression Testing: Ensuring that new changes or features do not negatively affect existing functionalities.
• Performance Testing: Testing software performance under various conditions (load, stress, scalability).
• Security Testing: Identifying vulnerabilities and assessing the software’s ability to protect data.
• Compatibility Testing: Ensuring the software works on different operating systems, browsers, or devices.
• Continuous Testing: Integrating testing into the development lifecycle to provide quick feedback and minimize bugs.
• Test Automation Frameworks: Tools and structures used to automate testing processes (e.g., TestNG, Appium).
19. VoIP (Voice over IP)
VoIP Protocols & Standards
• SIP (Session Initiation Protocol)
• H.323
• RTP (Real-Time Transport Protocol)
• MGCP (Media Gateway Control Protocol)
VoIP Hardware
• IP Phones (Desk Phones, Mobile Clients)
• VoIP Gateways
• Analog Telephone Adapters (ATAs)
• VoIP Servers
• Network Switches/ Routers for VoIP
VoIP Software
• Softphones (e.g., Zoiper, X-Lite)
• PBX (Private Branch Exchange) Systems
• VoIP Management Software
• Call Center Solutions (e.g., Asterisk, 3CX)
VoIP Network Infrastructure
• Quality of Service (QoS) Configuration
• VPNs (Virtual Private Networks) for VoIP
• VoIP Traffic Shaping & Bandwidth Management
• Firewall and Security Configurations for VoIP
• Network Monitoring & Optimization Tools
VoIP Security
• Encryption (SRTP, TLS)
• Authentication and Authorization
• Firewall & Intrusion Detection Systems
• VoIP Fraud DetectionVoIP Providers
• Hosted VoIP Services (e.g., RingCentral, Vonage)
• SIP Trunking Providers
• PBX Hosting & Managed Services
VoIP Quality and Testing
• Call Quality Monitoring
• Latency, Jitter, and Packet Loss Testing
• VoIP Performance Metrics and Reporting Tools
• User Acceptance Testing (UAT) for VoIP Systems
Integration with Other Systems
• CRM Integration (e.g., Salesforce with VoIP)
• Unified Communications (UC) Solutions
• Contact Center Integration
• Email, Chat, and Video Communication Integration
2 notes
·
View notes
Text
Face Blur Technology in Public Surveillance: Balancing Privacy and Security
As surveillance technology continues to evolve, so do concerns about privacy. One solution that addresses both the need for public safety and individual privacy is face blur technology. This technology automatically obscures individuals’ faces in surveillance footage unless there’s a legitimate need for identification, offering a balance between security and personal data protection.
Why Do We Need Face Blur Technology?
Surveillance systems are increasingly used in public spaces, from streets and parks to malls and airports, where security cameras are deployed to monitor activities and prevent crime. However, the widespread collection of images from public spaces poses serious privacy risks. Personal data like facial images can be exploited if not properly protected. This is where face blur technology comes in. It reduces the chances of identity theft, unwarranted surveillance, and abuse of personal data by ensuring that identifiable information isn’t exposed unless necessary. Governments, businesses, and institutions implementing face blur technology are taking a step toward more responsible data handling while still benefiting from surveillance systems (Martinez et al., 2022).
Key Technologies Behind Face Blur
Face blur technology relies on several key technologies:
Computer Vision: This technology enables systems to detect human faces in images and videos. Using machine learning algorithms, cameras or software can recognize faces in real-time, making it possible to apply blurring instantly.
Real-life example: Google’s Street View uses face blur technology to automatically detect and blur faces of people captured in its 360-degree street imagery to protect their privacy.
Artificial Intelligence (AI): AI plays a crucial role in improving the accuracy of face detection and the efficiency of the blurring process. By training models on large datasets of human faces, AI-powered systems can differentiate between faces and non-facial objects, making the blurring process both accurate and fast (Tao et al., 2023).
Real-life example: Intel’s OpenVINO toolkit supports AI-powered face detection and blurring in real-time video streams. It is used in public surveillance systems in places like airports and transportation hubs to anonymize individuals while maintaining situational awareness for security teams.
Edge Computing: Modern surveillance systems equipped with edge computing process data locally on the camera or a nearby device rather than sending it to a distant data center. This reduces latency, allowing face blurring to be applied in real-time without lag.
Real-life example: Axis Communications’ AXIS Q1615-LE Mk III surveillance camera is equipped with edge computing capabilities. This allows for face blurring directly on the camera, reducing the need to send sensitive video footage to a central server for processing, enhancing privacy.
Encryption: Beyond face blur, encryption ensures that any data stored from surveillance cameras is protected from unauthorized access. Even if footage is accessed by someone without permission, the identity of individuals in the footage remains obscured.
Real-life example: Cisco Meraki MV smart cameras feature end-to-end encryption to secure video streams and stored footage. In conjunction with face blur technologies, these cameras offer enhanced privacy by protecting data from unauthorized access.
How Does the Technology Work?
The process of face blurring typically follows several steps:
Face Detection: AI-powered cameras or software scan the video feed to detect human faces.
Face Tracking: Once a face is detected, the system tracks its movement in real-time, ensuring the blur is applied dynamically as the person moves.
Face Obfuscation: The detected faces are then blurred or pixelated. This ensures that personal identification is not possible unless someone with the proper authorization has access to the raw footage.
Controlled Access: In many systems, access to the unblurred footage is restricted and requires legal or administrative permission, such as in the case of law enforcement investigations (Nguyen et al., 2023).
Real-life example: The Genetec Omnicast surveillance system is used in smart cities and integrates privacy-protecting features, including face blurring. Access to unblurred footage is strictly controlled, requiring multi-factor authentication for law enforcement and security personnel.
Real-Life Uses of Face Blur Technology
Face blur technology is being implemented in several key sectors:
Public Transportation Systems: Many modern train stations, subways, and airports have adopted face blur technology as part of their CCTV systems to protect the privacy of commuters. For instance, London's Heathrow Airport uses advanced video analytics with face blur to ensure footage meets GDPR compliance while enhancing security.
Retail Stores: Large retail chains, including Walmart, use face blur technology in their in-store cameras. This allows security teams to monitor activity and reduce theft while protecting the privacy of innocent customers.
Smart Cities: In Barcelona, Spain, a smart city initiative includes face blur technology to ensure privacy in public spaces while gathering data to improve city management and security. The smart cameras deployed in this project offer anonymized data to city officials, allowing them to monitor traffic, crowd control, and more without compromising individual identities.
Journalism and Humanitarian Work: Media organizations such as the BBC use face blurring technology in conflict zones or protests to protect the identities of vulnerable individuals. Additionally, NGOs employ similar technology in sensitive regions to prevent surveillance abuse by oppressive regimes.
Public Perception and Ethical Considerations
Public perception of surveillance technologies is a complex mix of support and concern. On one hand, people recognize the need for surveillance to enhance public safety, prevent crime, and even assist in emergencies. On the other hand, many are worried about mass surveillance, personal data privacy, and the potential for abuse by authorities or hackers.
By implementing face blur technology, institutions can address some of these concerns. Studies suggest that people are more comfortable with surveillance systems when privacy-preserving measures like face blur are in place. It demonstrates a commitment to privacy and reduces the likelihood of objections to the use of surveillance in public spaces (Zhang et al., 2021).
However, ethical challenges remain. The decision of when to unblur faces must be transparent and subject to clear guidelines, ensuring that this capability isn’t misused. In democratic societies, there is ongoing debate over how to strike a balance between security and privacy, and face blur technology offers a middle ground that respects individual rights while still maintaining public safety (Johnson & Singh, 2022).
Future of Face Blur Technology
As AI and machine learning continue to evolve, face blur technology will become more refined, offering enhanced accuracy in face detection and obfuscation. The future may also see advancements in customizing the level of blurring depending on context. For instance, higher levels of obfuscation could be applied in particularly sensitive areas, such as protests or political gatherings, to ensure that individuals' identities are protected (Chaudhary et al., 2023).
Face blur technology is also expected to integrate with broader privacy-enhancing technologies in surveillance systems, ensuring that even as surveillance expands, personal freedoms remain protected. Governments and businesses that embrace this technology are likely to be seen as leaders in ethical surveillance practices (Park et al., 2022).
Conclusion
The need for effective public surveillance is undeniable in today’s world, where security threats can arise at any time. However, the collection of facial images in public spaces raises significant privacy concerns. Face blur technology is a vital tool in addressing these issues, allowing for the balance between public safety and individual privacy. By leveraging AI, computer vision, and edge computing, face blur technology not only protects individual identities but also enhances public trust in surveillance systems.
References
Chaudhary, S., Patel, N., & Gupta, A. (2023). AI-enhanced privacy solutions for smart cities: Ethical considerations in urban surveillance. Journal of Smart City Innovation, 14(2), 99-112.
Johnson, M., & Singh, R. (2022). Ethical implications of face recognition in public spaces: Balancing privacy and security. Journal of Ethics and Technology, 18(1), 23-37.
Martinez, D., Loughlin, P., & Wei, X. (2022). Privacy-preserving techniques in public surveillance systems: A review. IEEE Transactions on Privacy and Data Security, 9(3), 154-171.
Nguyen, H., Wang, T., & Luo, J. (2023). Real-time face blurring for public surveillance: Challenges and innovations. International Journal of Surveillance Technology, 6(1), 78-89.
Park, S., Lee, H., & Kim, J. (2022). Privacy in smart cities: New technologies for anonymizing public surveillance data. Data Privacy Journal, 15(4), 45-61.
Tao, Z., Wang, Y., & Li, S. (2023). AI-driven face blurring in public surveillance: Technical challenges and future directions. Artificial Intelligence and Privacy, 8(2), 123-140.
Zhang, Y., Lee, S., & Roberts, J. (2021). Public attitudes toward surveillance technology and privacy protections. International Journal of Privacy and Data Protection, 7(4), 45-63.
2 notes
·
View notes
Text
Drones have changed war. Small, cheap, and deadly robots buzz in the skies high above the world’s battlefields, taking pictures and dropping explosives. They’re hard to counter. ZeroMark, a defense startup based in the United States, thinks it has a solution. It wants to turn the rifles of frontline soldiers into “handheld Iron Domes.”
The idea is simple: Make it easier to shoot a drone out of the sky with a bullet. The problem is that drones are fast and maneuverable, making them hard for even a skilled marksman to hit. ZeroMark’s system would add aim assistance to existing rifles, ostensibly helping soldiers put a bullet in just the right place.
“We’re mostly a software company,” ZeroMark CEO Joel Anderson tells WIRED. He says that the way it works is by placing a sensor on the rail mount at the front of a rifle, the same place you might put a scope. The sensor interacts with an actuator either in the stock or the foregrip of the rifle that makes adjustments to the soldier’s aim while they’re pointing the rifle at a target.
A soldier beset by a drone would point their rifle at the target, turn on the system, and let the actuators solidify their aim before pulling the trigger. “So there’s a machine perception, computer vision component. We use lidar and electro-optical sensors to detect drones, classify them, and determine what they’re doing,” Anderson says. “The part that is ballistics is actually quite trivial … It’s numerical regression, it’s ballistic physics.”
According to Anderson, ZeroMarks’ system is able to do things a human can’t. “For them to be able to calculate things like the bullet drop and trajectory and windage … It’s a very difficult thing to do for a person, but for a computer, it’s pretty easy,” he says. “And so we predetermined where the shot needs to land so that when they pull the trigger, it’s going to have a high likelihood of intersecting the path of the drone.”
ZeroMark makes a tantalizing pitch—one so attractive that venture capital firm Andreesen Horowitz invested $7 million in the project. The reasons why are obvious for anyone paying attention to modern war. Cheap and deadly flying robots define the conflict between Russia and Ukraine. Every month, both sides send thousands of small drones to drop explosives, take pictures, and generate propaganda.
With the world’s militaries looking for a way to fight back, counter-drone systems are a growth industry. There are hundreds of solutions, many of them not worth the PowerPoint slide they’re pitched from.
Can a machine-learning aim-assist system like what ZeroMark is pitching work? It remains to be seen. According to Anderson, ZeroMark isn’t on the battlefield anywhere, but the company has “partners in Ukraine that are doing evaluations. We’re hoping to change that by the end of the summer.”
There’s good reason to be skeptical. “I’d love a demonstration. If it works, show us. Till that happens, there are a lot of question marks around a technology like this,” Arthur Holland Michel, a counter-drone expert and senior fellow at the Carnegie Council for Ethics in International Affairs, tells WIRED. “There’s the question of the inherent unpredictability and brittleness of machine-learning-based systems that are trained on data that is, at best, only a small slice of what the system is likely to encounter in the field.”
Anderson says that ZeroMark’s training data is built from “a variety of videos and drone behaviors that have been synthesized into different kinds of data sets and structures. But it’s mostly empirical information that’s coming out of places like Ukraine.”
Michel also contends that the physics, which Anderson says are simple, are actually quite hard. ZeroMark’s pitch is that it will help soldiers knock a fast-moving object out of the sky with a bullet. “And that is very difficult,” Michel says. “It’s a very difficult equation. People have been trying to shoot drones out of the sky [for] as long as there have been drones in the sky. And it’s difficult, even when you have a drone that is not trying to avoid small arms fire.”
That doesn’t mean ZeroMark doesn’t work—just that it’s good to remain skeptical in the face of bold claims from a new company promising to save lives. “The only truly trustworthy metric of whether a counter-drone system works is if it gets used widely in the field—if militaries don’t just buy three of them, they buy thousands of them,” Michel says. “Until the Pentagon buys 10,000, or 5,000, or even 1,000, it’s hard to say, and a little skepticism is very much merited.”
3 notes
·
View notes
Text

The universe on display: The powerful instruments that allow us to observe the cosmos
Starting today, the Earth will be passing through a meteor shower. But in astronomy, the human eye is very much a limited tool. But increasingly powerful instruments are allowing us to peer ever deeper into the cosmos and ever further back in time, shedding new light on the origins of the universe.
Today, scientists are able to observe an exoplanet orbiting its star, an individual galaxy and even the entire universe. "The universe is actually mostly empty space," says Jean-Paul Kneib, a professor at EPFL's Laboratory of Astrophysics. "There isn't much that's hidden."
The key is to know what you're looking for, build the right instrument, and look in the right direction. And then to do a little housekeeping.
"Our galaxy sits in the foreground of our field of vision, blocking our view beyond it," explains Kneib. "So if we want to map hydrogen in the early universe, for example, we first have to model this entire foreground then remove it from our images until we obtain a signal a million times smaller than the one emitted by the Milky Way."
Galileo could draw only what he saw with his telescope. But today, astronomers can see the universe in its entirety, right back to its very beginnings. This is largely because of rapid advancements in the instruments they use. And more developments are expected in the years ahead.
The James Webb Space Telescope (JWST), launched in December 2021, aims to observe events that happened 13 billion years ago when the first stars and galaxies were forming. The Square Kilometre Array (SKA) radio telescope—currently under construction and scheduled for completion by the end of the decade—will look back even further to a time when there were no stars and the cosmos contained mainly hydrogen—the element that makes up 92% of all atoms in the universe.
"An easy way to detect this gas is to operate in the radio frequency range, which is exactly what the SKA will do," says Kneib. "The aim is to detect a signal a million times smaller than the foreground signals."
Another project in the pipeline is the Laser Interferometer Space Antenna (LISA), run by the European Space Agency (ESA). Scheduled for launch in 2035, the antenna will observe gravitational waves, shedding light on the growth of black holes and possibly the waves created just after the Big Bang.
Playing digital catch-up
These new instruments wouldn't be so enlightening without advancements in other fields. "As things stand, we don't have the software to process data from the SKA," says Kneib, who's confident that we'll get there eventually thanks to progress in computer and computational science, artificial intelligence (AI) and processing power. AI is invaluable for sorting through vast quantities of data to find an interesting anomaly and for calculating the mass of galaxies, for example.
"Scientists can use the gravitational lensing effect, whereby a large object bends light from a distant source, to calculate the mass of galaxy clusters to within a range of one percent, just as if they were using a scale," explains Kneib. "And we can train AI models to spot distortions in images caused by gravitational lenses. Given that there are probably 200 billion galaxies in the universe, that's a huge help—even if we can measure the mass of only one galaxy in every thousand."
But do the images we see depict what's really out there? A famous image published in 2019 showed a donut-shaped ring of light surrounding a black hole. Would we actually see that ring if we got close to it?
"It wasn't an optical photo," says Kneib. "It was a purely digital rendering. In order to accurately observe the millimeter-wavelength signals emitted by the black hole, scientists had to combine multiple ground-based telescopes to create one roughly the size of the globe. The image was then reconstructed via interferometry [a measurement method using wave interference].
"But the image nevertheless represents a real signal, linked to the amount of matter in the dust cloud surrounding the black hole. In simple terms, the dark part is the black hole and the lighter part is the matter orbiting it."
Seeing in four dimensions
"Calculations are only part of the equation in astronomy—you need to be able to visualize things, which also helps you check that your calculations are correct," says Kneib, who is capable of reading the majestic image of the Lagoon Nebula, situated 4,000 light-years away, like a book.
"That image was produced using optical observations at different wavelengths to depict the various gases. Of course, there was a bit of artistry involved in enhancing the colors. But the image also has a great deal of significance for physicists. The colors indicate the presence of different gases: red for hydrogen, blue for oxygen and green for nitrogen. The compact, black areas contain large quantities of dust. These are typically the regions where stars form."
Visualization is especially important when observing objects in more than two dimensions. "By studying the cosmos in three dimensions, we're able to measure the distance between celestial objects," says Kneib.
In early April, scientists working on the Dark Energy Spectroscopic Instrument (DESI) project—including astrophysicists from EPFL—announced they had created the largest ever 3D map of the universe's galaxies and quasars.
But that's not all: researchers are also studying the universe in the fourth dimension—time—and, in doing so, opening up incredible possibilities for observing bright yet fleeting phenomena. "For example, we don't really understand the origin of fast radio bursts, which are incredibly bright blasts of electromagnetic radiation that last only a few seconds at most, and sometimes just a fraction of a millisecond," says Kneib.
Will we ever find life on an exoplanet? Kneib replies, "With infrared interferometry, there's a very real prospect that we could take a photo of a planet orbiting around another star. The image would likely be blurry, but we'd be able to observe and characterize features such as clouds and structural variations on the planet's surface. That's definitely a possibility, maybe 20 or 30 years from now."
When it comes to some fundamental questions, however, we're unlikely to find the answers through imaging alone. Why is the universe expanding at an accelerating rate? Is it because of dark energy? Why is 80% of matter invisible? Are we completely wrong about gravity? Future generations of astrophysicists will keep their eyes trained on the skies or glued to their screens as they try to unravel the deepest mysteries of our universe.
IMAGE: The Lagoon Nebula. Credit: NASA, ESA, STSCI
4 notes
·
View notes